| Progress |
Acquisition of Communication and Recognition Skills
|
|
|
|
The progress of the project is documented and reported in several different ways. On this website you can find the relevant parts of the Executive Summaries of the Periodic Activity Reports, the annual reports that the consortium must submit to the European Commission. The summaries will be published after the report has been formally accepted by the Commission.
On this website you can also find the annual reports on the results of the research that are produced by the individual workpackages. These reports are also known as the Deliverables of the project.
Last but not least, the results of the research are reported in papers in workshops, conferences, journals and books. All papers published so far can be accessed via the Documents tab on the home page.
| Executive Summary of the year-1 Activity Report |
|---|
During
the first year baseline modules were developed and delivered for front-end
processing and information discovery that
were integrated in a system that
allows us to conduct experiments to simulate language acquisition. For four
languages (Dutch, Swedish, Finnish and English) a small corpus of infant
directed and adult directed speech has been recorded for use in experiments with
language acquisition. The integrated system and the corpora have been used to
perform a set of baseline experiments that have shown that a properly designed
computational model can learn to distinguish between utterances that refer to
different objects on the basis of very general learning principles. Linguistic
representations are emergent properties of the model, rather than information
that is built into the model before the learning starts.
The
processing and internal representations of the model can be mapped on a general
model of speech processing that is compatible with the memory-prediction theory
and at the same time reflects the results of a large body of psycholinguistic
and psychological experiments. This memory and processing model is shown
schematically in Fig. 1.
Substantial
progress has been made in developing a novel approach to signal-driven structure
discovery in WP2. For the moment, this has resulted in a patent application and
operational software that is ready for integration in the system for conducting
language acquisition experiments.
A
very important dissemination activity took place at the end of the first year of
ACORNS. Co-funded by the European Science Foundation (ESF) and the Netherlands
Organisation for Scientific Research (NWO) an on-invitation only workshop was
organised. This three day workshop with the title Models of language
evolution, acquisition, and processing was held in
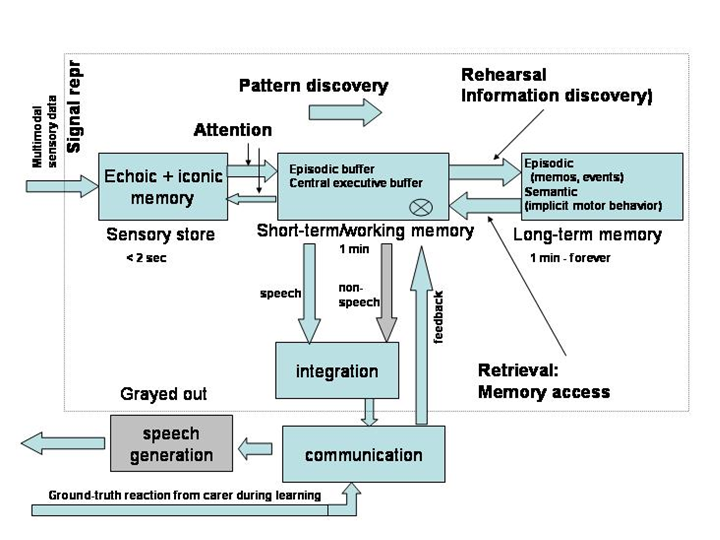
Figure 1 Schematic overview of the memory and processing architecture in ACORNS.
In
the first year we have constructed operational modules for acoustic
pre-processing, for information discovery and for conducting language
acquisition experiments. In addition, we have created an initial version of a
learning agent (an artificial baby, as it were) that, in interaction with a
caregiver (also artificial) can learn language by processing multimodal input.
The eventual memory architecture of the learner is shown in Figure 1. Quite
naturally, the implementation created in the first year of the project is
somewhat simpler. To make possible a form of reinforcement learning, the
learning agent indicates what he has understood, and the caregiver gives
feedback about his/her satisfaction with the learners performance. The set-up
of the learning experiments is shown in Figure 2. In order to be able to conduct
biologically and cognitive learning experiments we have recorded small corpora
of infant directed and adult directed speech in four languages (Dutch, English,
Finnish and Swedish) and used the recordings for conducting experiments. The
results of the experiments conducted during the last two months of the first
year used only one approach to pattern and information discovery, based on
Non-negative Matrix Factorisation, a technique reminiscent of Latent Semantic
Analysis. The results of the experiments show that a learning agent can discover
structure in input speech and relate that to some 10 different objects.
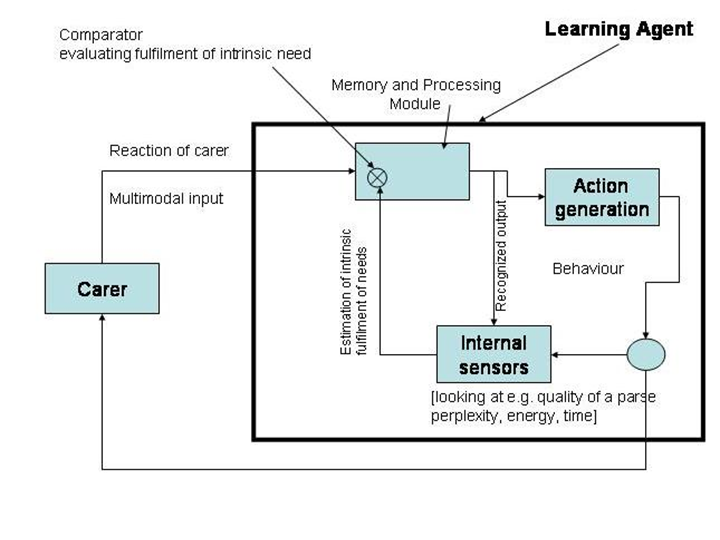
Figure
2
Schematic overview of the learning process.
| Executive Summary of the year-2 Activity Report |
|---|
While
the results of the research in the first year of the project were very
encouraging, inevitably we encountered a number of issues that required special
attention during the second year.
Perhaps
the most obvious one was that in the first year we had taken a shortcut with
respect to the representation of the input in the visual (and tactile) channels.
To bootstrap the experiments it was decided to represent the non-audio input in
the form of crisp symbolic tags that identify the reference of the speech
utterances. Yet, it had been clear all the time that this approach was not
plausible from a cognitive or biological point of view. Therefore, substantial
effort was spent in the second year to develop more plausible representations
(cf. Deliverable 5.4.2).
A
second major finding in the first year was that all existing theories and models
of language acquisition and communication are so abstract and incomplete that
all allow for several algorithmic implementations.
On the one hand this is advantageous, because it made it possible to show
the correspondences between the models developed in Psychology and the
Memory-Prediction Theory (cf. Figs. 1 and 2). On the other hand, the need to
investigate several algorithmic approaches made it impossible to integrate all
results of the individual work packages in a single integrated system that
simulates language acquisition. In year-2 substantial progress was made in
relating independently developed memory and processing architectures (cf.
Deliverable 3.2).
Even
if alternative algorithms for discovering and representing structure and
information in speech fit in the same abstract models of memory and processing,
they may still require different software implementations of the architectures
sketched in Figs. 1 and 2. For this reason it is not useful to try and develop a
unique implementation of the memory architecture. Therefore, it was decided that
ACORNS will take a two-pronged strategy: we will try to integrate as many
findings as possible in an increasingly more powerful and plausible agent that
simulates language acquisition, while there may be other results that do provide
insight in processes but that cannot be integrated in an operational system.
Moreover, we will construct parallel versions of the language acquisition agent,
based on alternative strategies for information discovery and integration. These
versions may share some modules, but evidently not all. One module that will be
shared is the acoustic feature extraction under development in WP1.
Parallel implementations of the language acquisition agent can be compared in many different manners. One option would be to stage a competition between alternative implementations, with the eventual goal to select the best. However, we feel that the state of the art in simulating language acquisition is not sufficiently advanced to allow for establishing clear-cut performance criteria with which competing instantiations could be compared. For that reason, we decided to focus the comparison on the insights in language acquisition and language processing that can be gleaned from each of them. This also makes it possible to treat the partial approaches in a fair manner, since these too will contribute to advancing our understanding.
Guided
by the results of the experiments in Year-1 and the goals set for Year-2 an
extended corpus of speech utterances was recorded, annotated (as far as
necessary) and made available to the partners for conducting experiments. The
Year-2 corpus was recorded in Dutch, English and Finnish. Each corpus comprises
recordings from 10 different speakers. Four of these are the same speakers as in
the Year-1 corpus, enabling cognitively and biologically plausible experiments
with more advanced language acquisition. Each of the four speakers acted
out 2000 utterances constructed to contain up to four key words. Six
additional speakers produced a different subset of 600 utterances each.
To
address the issue of too crisp and unique visual/semantic representations we
have created a set of 64 visual/semantic features that can be used to represent
the meaning or grounding of the utterances in the Year-1 and Year-2 corpora. For
the Year-1 corpus, where each utterance refers to a single object, the features
can be used to create ambiguity: each object can be referred to with multiple
combinations of features. The use of features also makes it possible to
represent similarities and differences between object classes: dog and
cat can be given representations that are more similar than, for example,
car and mamma. In addition, the use of features makes it possible to
link multiple attributes to objects (e.g. a big green frog, where
big and green are attributes of the object frog).
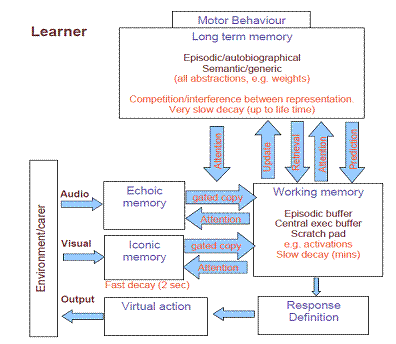
|
Figure
1
Hierarchical modular memory
and processing architecture that reflects the results from research in
Psychology on Memory, especially with regards to language processing
|
All
partners worked to develop and elaborate methods for discovering patterns,
structure and information in speech signals grounded by corresponding tags or
semantic feature vectors. Virtually all conventional methods for mining data for
meaningful patterns that are known from the literature assume that a massive
amount of data is available at the start of the process and that all data can be
accessed repeatedly. These assumptions are not compatible with biological and
cognitive knowledge about how living agents learn. Therefore, much of the
research in the second year was dedicated to making the structure discovery
processes incremental, in the sense that each individual input utterance was
heard only once. Of course, the presence of working and long-term memory in the
architecture shown in Fig. 1 makes it possible to process input utterances
multiple times, as long as a suitable representation remains accessible in the
memory. We have succeeded in developing incremental representations of most
pattern discovery algorithms under investigation (Non-negative Matrix
Factorisation [NMF], DP-ngrams and Concept Matrices). This makes it possible to
evaluate the learning behaviour of a specific pattern discovery algorithm by
comparing the algorithms interpretation of a novel stimulus with the ground
truth.
The
pattern discovery algorithms under investigation can be characterised in terms
of the stage at which processing moves from sub-symbolic representations to
representations that can be interpreted as meaningful symbols. We have come to
the conclusion that approaches which rely on an early switch to symbolic
processing (such as Computational Mechanics Modelling and multigran models)
suffer from too large a symbol alphabet that must be considered in bottom-up
processing of speech signals. Experiments with several conceptually different
structure discovery methods showed that no existent method can deal with
alphabets of more than about 100 symbols. Even with lower numbers of symbols
existent methods fail if the symbols in the input stream are subject to
uncertainty, which results in a very large number of different sequences. We
have extended the theory underlying Computational Mechanics Modelling to enable
it to cope with approximate causal states, i.e., symbol sequences that are
similar to a degree that allows them to be considered as instantiations of a
unique underlying sequence.
Algorithms
(such as NMF and DP-ngrams) that postpone the switch to a later stage (when the
number of potentially meaningful symbols is much smaller) appear to have a clear
advantage in processing highly variable signals such as natural speech. .
.
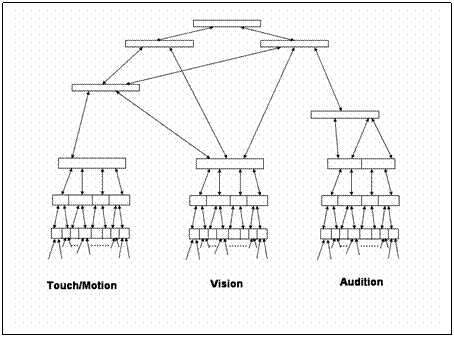
Figure 2 One possible view of the cortical hierarchy in the Memory-Prediction Framework. (After Hawkins, 2004)
The
memory architecture designed in Year 1 was elaborated and made more concrete
thanks to the research in Year 2. The updated model is shown in Fig. 1. We also
made progress in establishing correspondences between the memory architecture
based on the results of behavioural psychological research (basically, the
architecture in Fig. 1) and the memory architecture suggested by the
memory-prediction framework (sketched in Fig. 2). We analysed the seemingly
incompatible architectures on the three levels suggested by Marr. It appears
that both (classes of) models are so abstract and incompletely specified at the
computational level that no existing theory can impose very strong constraints
on the choices made at the algorithmic or the implementation levels.
From the results of the experiments with pattern discovery procedures it has become evident that multi-layer architectures have an advantage over single-layer ones. Also, it is difficult to imagine how a single-layer representation of language could be effective. For that reason we have investigated several multi-layer approaches, including multi-layered versions of NMF as well as Self Organising Maps and Restricted Boltzmann Machines. Interesting issues include the question to what extent old representations remain accessible after newer, more powerful ones have been formed, and whether processes change over time or between levels of representation. These issues are central in all cognitive science research in language acquisition. The memory and processing architecture that we have built allows us to test all alternative hypotheses. The results obtained in year-2 suggest that none of the possibilities can be ruled out.
ACORNS
is supported by a multidisciplinary advisory committee. Towards the end of
year-2, in time for guidance to have effect on the course of the research, we
have convened meetings with the members of the SAC, to discuss the most
promising directions and objectives for the last year. The results of these
meetings have contributed substantially to the formulation of the concrete plans
for year 3.
Last updated: 28 January 2009. Please contact Els den Os with any comments, complaints, or reports of broken links.